
We Design and Deliver Production-Grade Automation and AI Systems
From architecture to deployment, we take responsibility for systems that must work - reliably and without surprises.
You may recognize this
The system does not feel broken at first.
Orders still come in. Leads still arrive. The team still gets work done. But slowly, the owner has to check more things manually just to keep the business moving.
Follow-ups depend on people remembering
A lead, order, or customer request can slip because the next step lives in chat, memory, or a spreadsheet.
The team asks the same questions again
Status, ownership, and next actions are not obvious, so coordination becomes another layer of work.
Reports create more questions than answers
Numbers exist, but no one is fully sure which version is current, complete, or trusted.
Growth creates more control work
More sales, channels, or staff should create leverage, but instead they create more things to monitor manually.

Before and after
The goal is not to make the business more complicated.
A good system should make the business easier to run, not harder to explain.
Before LaPage
Work happens, but control depends too much on manual effort.
Customer data is scattered across tools, chats, forms, and spreadsheets.
Important follow-ups depend on someone remembering the next step.
Reports take time to prepare and still do not feel fully reliable.
The owner has to keep asking for updates to understand what is happening.
After a clearer system
The team has a more stable way to see, route, and improve the work.
Customer and operational data move through a clearer structure.
Repeated steps are automated, with human review where it matters.
Dashboards and alerts show what needs attention earlier.
The business becomes easier to operate, measure, and improve over time.
What Better Systems Change
The goal is not more software. The goal is a business that is easier to understand, coordinate, and improve.
Clarity
Everyone knows what is happening
Teams can see the status of work, customers, exceptions, and next steps without constant manual checking.
Ownership
Data and workflows are easier to control
Important business information moves through a structure the team can understand and improve.
Reliability
Important work stops depending on memory
The system handles repeated steps, flags exceptions, and reduces the risk of silent failure.
Decisions
Leaders get a clearer picture
Reporting and operational visibility help the business act earlier, not only after problems appear.

What We Help Build
We connect the practical parts of the business: customer journeys, internal workflows, data, automation, and the platforms that support them.
Automation Systems
Workflow orchestration for lead handling, approvals, operational routing, and exception management.
Cross-platform triggers and validation
Fallback logic for edge cases
Human review where automation should pause
Operational Platforms
Internal tools that give teams clearer control over process state, system actions, and support workflows.
Custom interfaces around real operations
Role-aware workflows and safeguards
Usable without engineering handholding
Data Pipelines and Reporting
Structured reporting foundations that normalize input from multiple systems and preserve auditability.
Consistent KPI definitions
Data quality checks and normalization
Reporting layers teams can trust
Production Infrastructure
Hosting and runtime foundations designed for resilience, controlled deployment, and visibility under load.
Environment hardening and rollout planning
Monitoring and recovery readiness
Infrastructure that supports change safely
Capabilities
Technical capability matters, but only when it supports clearer operations and stronger business ownership.
AI and Automation Systems
Designed for business workflows that need validation, escalation paths, and dependable execution.
Production Infrastructure
Built to remain stable through deployment, growth, operational pressure, and failure recovery.
Data and System Integration
We structure reliable data movement across tools, teams, and reporting surfaces.
Custom Operational Platforms
Built around actual operational use, not temporary interfaces that collapse as complexity increases.
How We Work
We untangle the operation first, then design and build the system around it.
Step 01
Assessment and System Mapping
Understand current systems, workflows, and constraints.
Step 02
Architecture and Risk Planning
Design structure with clear risk considerations.
Step 03
Implementation
Build systems with reliability and maintainability in mind.
Step 04
Deployment and Stabilization
Ensure smooth rollout and operational readiness.
Step 05
Ongoing Support
Maintain, monitor, and evolve systems as needed.

What Clients Receive
The output is not just shipped code. It is a clearer way for the team to run, monitor, and improve the business.
A clear map of current workflows, tools, and constraints
A practical system plan before implementation begins
Automation and integrations designed around real operations
Dashboards, alerts, or reporting where visibility matters
Documentation that helps the team own the system
A support path for stabilization and future changes
Examples of Systems We Build
A few examples of how messy operations can become clearer, more reliable systems.
Automating Lead Handling System
Problem
Manual and inconsistent lead processing across channels.
Constraint
Multiple platforms with conflicting lead states.
Approach
Centralized workflow with validation and fallback logic.
Outcome
Reliable routing and fewer missed leads.
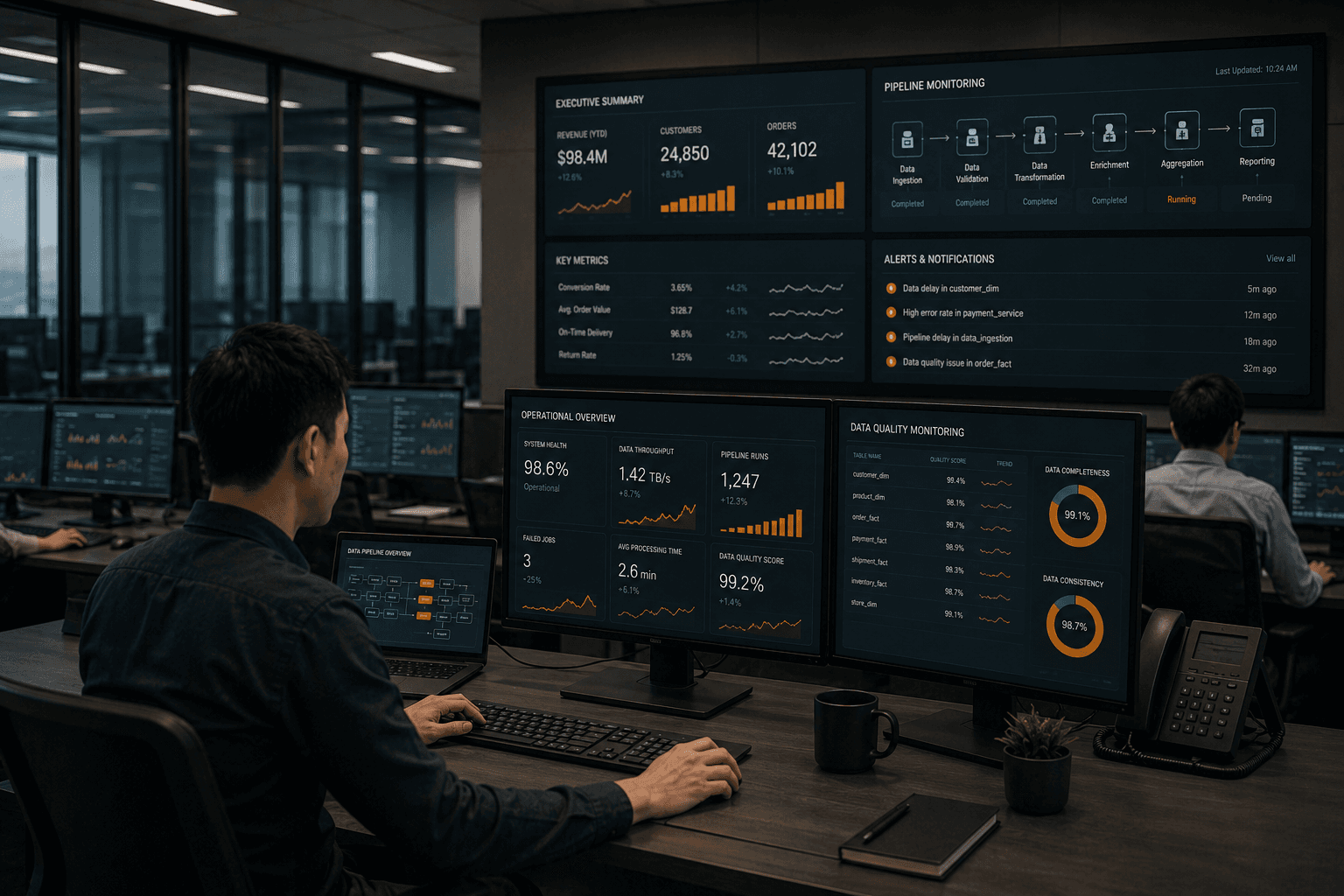
Operations Monitoring and Alerts
Problem
Delayed response to system failures and data issues.
Constraint
Limited visibility across services and teams.
Approach
Unified monitoring layer with incident thresholds.
Outcome
Faster detection and controlled recovery.

Multi-Source Reporting Pipeline
Problem
Fragmented reporting and inconsistent KPIs.
Constraint
Data lived across tools with uneven quality.
Approach
Structured pipeline with normalization and audit trails.
Outcome
Consistent reporting and dependable decision data.
Why LaPage Digital
We bring engineering discipline to business problems without making the solution harder to understand.
We design systems from the backend outward - where reliability actually lives.
Experience delivering systems that operate in real production environments.
Strong integration across automation, infrastructure, and data layers.
We prioritize reliability over trends, even when it means saying no to unnecessary complexity.
Systems-focused technical leadership
About the Founder
LaPage Digital is led by a former engineer focused on production systems, automation reliability, and operational clarity. The work centers on designing systems that can be depended on - not just delivered. This includes building stable infrastructure, structuring automation that doesn’t fail silently, and ensuring systems remain maintainable as they evolve. The approach is grounded in backend systems thinking, where performance, failure handling, and long-term operation are treated as first-class concerns.
I think about business systems the way engineers think about aircraft.
A small issue in one part of the plane should not bring down the whole system.
The passenger screen, the navigation system, the engine controls, and the safety systems all have different responsibilities. They are separated for safety, but connected enough to work together.
That is also how good business systems should be built.
Your customer data, automation, reporting, internal tools, and infrastructure should not be tangled together in a way that makes every change risky.
Each part should be clear, reliable, and replaceable — but still connected to the wider business.
This is how LaPage approaches system design: build carefully for today, while keeping the business scalable and adaptable for later.
Questions Before Starting a System Clarity Audit
When is this kind of engagement a good fit?
Usually when operations already depend on multiple systems, there is visible process strain, and reliability matters more than shipping a quick experiment.
Do you only work on AI projects?
No. AI is only one layer. Many engagements involve workflow design, integration, infrastructure, data reliability, and the operational controls around them.
Can you work with existing systems instead of replacing them?
Yes. A large part of the work is designing around current constraints, improving reliability, and reducing disruption while the system evolves.
What happens after launch?
We plan for stabilization, visibility, and ongoing support so the team is not left with a black box after deployment.
Start with a System Clarity Audit
We map how your work, data, customers, and tools currently move — then identify the first system improvements that can reduce manual checking and give you better control.